
BSV Insights 0002: Kilowatts to Compute: Data Centers on Earth and in Orbit
Data centers are now a power and cooling problem. The backbone of global compute will be built on Earth, enabled by nuclear power. Edge compute and mass access will be enabled by advances in orbit.



Over the past decade, data centers have become one of the largest and fastest-growing industrial electrical loads on the planet. These centers were originally warehouses of servers attached to office parks. They have now become megawatt to gigawatt-scale systems where power delivery and thermal management are foundational constraints on design, location, and economics.

Artificial intelligence has driven the recent acceleration in this transition. Training and inference workloads for large language models concentrate unprecedented compute density into single facilities, increasing rack power draws by a factor of about ten. Nearly all electrical input into modern servers that power logic and storage is ultimately converted to heat that must be rejected to the environment.
As a result, modern data centers are best understood as tight couplings of energy supply, thermal management, and compute systems. This report defines the basics of what a modern data center is. From that foundation, it examines the constraints now shaping the industry, including where data centers can be built, how they scale, power demand, water scarcity for evaporative cooling, and environmental permitting.
Two solution paths are emerging in parallel:
On Earth, increasingly dense compute is being combined with advanced liquid and immersion cooling*, and is seeking reliable and low marginal cost power, most notably nuclear, to anchor the next generation of infrastructure.
In orbit, there is interest in leveraging continuous solar power and radiative cooling in vacuum to support specialized compute workloads through large orbital platforms, or through distributed constellations building on how Starlink scales edge satellite connectivity.
*On Earth, alternative coolants such as helium-4 and helium-3 play no practical role in AI data centers. Their use is confined to quantum computing and superconducting systems, where logic elements must be maintained at cryogenic temperatures.
Goldman Sachs Research frames data centers not just as a technology infrastructure but as a new industrial power load and asset class, forecasting that global electricity demand from data centers will increase by roughly 165 % by 2030 versus 2023.1 McKinsey research anticipates $6.7 trillion in global investment by 2030 to keep pace with the demand for compute power.2 At the same time, hyperscale firms are backing dedicated power generation to support this surge. For example, Google’s agreement with Kairos Power and TVA to secure 50 MW of advanced nuclear capacity that could eventually expand to 500 MW.3 More recently, companies like SpaceX and Starcloud are bullish on compute in orbit. These engineering and energy dynamics are now central to investment theses across power, grid, and data center markets.
OUTLINE
DATA CENTERS EXPLAINED
A data center is a physical structure for computer systems, including for computation, data storage, and related communications components. These systems require supporting infrastructure for power supply, communication connections, environmental controls (e.g., cooling, fire suppression), and security. Data centers are the foundation of the digital infrastructure underlying the modern economy, supporting the computing demands for cloud services, video streaming, blockchain and crypto mining, machine learning, and virtual reality.
Every modern data center, regardless of size or location, is composed of three tightly coupled subsystems:
Power delivery
Compute and networking
Thermal management
The performance, cost, and scalability of a data center is determined by how efficiently these subsystems function individually and as an integrated whole.
Power Delivery
Power can be supplied from the grid, from on-site generation, or from a combination of both. From there, power is stepped down, conditioned, and distributed to servers with high reliability. Data center power levels are typically sized in tens to hundreds of megawatts. Continuous stable power is critical for data centers and is provided by uninterruptible power supplies (UPS), which are battery systems used to bridge supply between a power loss and activation of back-up generators or restoration of power. Power distribution units (PDUs) take the power input and distribute it to numerous servers, switches, and other equipment. PDUs are often equipped to monitor consumption and efficiency. At hyperscale, power availability is the chief limiting factor. The ability to secure reliable, high-capacity electrical supply is driving where data centers will be built and how large they can become. Nuclear energy has become the target solution, where in-space solutions look to continuous solar energy availability.
Compute and Networking
The compute system consists of servers arranged in racks, connected by high-bandwidth, low-latency networks. Historically, data centers were dominated by general-purpose central processing units (CPUs). Today, AI workloads are driving rapid adoption of graphics processing units (GPUs) and application-specific integrated circuits (ASICs). These devices deliver much higher performance per rack but at dramatically higher power densities.
CPUs are optimized for low-latency, sequential tasks. CPUs have a small number of powerful cores designed to execute complex instruction streams quickly, making them ideal for operating systems, databases, and interactive workloads where decisions must be made step-by-step.
GPUs trade latency for parallel processing capability. Instead of a handful of powerful cores, GPUs contain hundreds to thousands of simpler cores designed to perform the same operation on many data elements simultaneously. This architecture maps naturally onto the linear algebra underlying modern machine learning where the same computation is repeated across large datasets.
ASICs are purpose-built chips designed to execute a narrow class of computations with much higher energy efficiency than general-purpose CPUs or GPUs, by eliminating unnecessary logic and control overhead. As data center workloads mature, the compute stack shifts from CPUs to GPUs to ASICs, trading flexibility for efficiency and helping to ease the power and thermal constraints surrounding compute.
 | by Abhishek Jain | Medium")
GPUs deliver orders-of-magnitude higher throughput for AI workloads by exploiting massive parallel processing, but at the cost of highly increased power density per rack and a much heavier dependence on high-bandwidth networking to keep thousands of cores fed with data. As a result, modern AI data centers are no longer constrained by compute alone as they are increasingly limited by power delivery, thermal management, and network technology.
These constraints become clearer when distinguishing between training and inference workloads. Modern AI workloads divide naturally into training and inference, which occur in sequence and serve different roles. Training is the process of building a model by repeatedly adjusting its parameters using large datasets. Training is extremely compute- and energy-intensive and typically runs in concentrated bursts on large, centralized clusters. Once trained, the model is deployed, and inference is the ongoing execution of that model to answer user queries, generate outputs, or make decisions. While training happens relatively infrequently, inference runs continuously and at massive scale, often serving billions of requests by users from a single trained model. Training creates the model and inference uses it. Training favors centralized, power-dense, latency-tolerant data centers, while inference increasingly prioritizes efficiency and proximity to users, pushing compute toward more distributed and edge-oriented deployments.
Training concentrates enormous amounts of compute into relatively few locations, often running for extended periods across thousands of GPUs or accelerators. Training favors centralized power-dense centers, and can tolerate latency. Dense power delivery, advanced cooling, and ultra-fast internal networking are critical.
Inference executes trained models in response to user queries. Individual inference tasks require far less compute than training, but they occur continuously and are sensitive to latency. Inference favors efficiency and proximity to users pushing compute toward more distributed and edge-oriented deployments.

Training versus inference drives data center architecture. Training clusters drive rack power densities from historical levels of roughly 5 to 10 kW per rack to 30 to 50 kW, with frontier AI systems approaching or exceeding 100 kW per rack. At these densities, air cooling becomes impractical and liquid cooling becomes essential. Inference workloads, by contrast, favor efficiency and proximity to the user, favoring distributed compute and edge deployment. As rack densities rise and workloads specialize, compute design increasingly dictates where data centers can be built, how they are powered, and how heat is rejected. This coupling between compute architecture and infrastructure underlies the emerging split between large, centralized facilities optimized for training and smaller, distributed systems optimized for inference, both on Earth in orbit.
Thermal Management
Almost all of the electrical power delivered to servers ultimately becomes heat within the facility. Logic operations, memory access, power conversion losses, and even useful computation dissipate energy as heat that must be transported away and rejected to the environment.
Thermal management systems perform this task in stages. Heat is first extracted at the chip level, then removed at the rack level, and then finally rejected at the facility level. Historically, air cooling was used but, as power densities rose, this became insufficient. Modern solutions require liquid cooling once rack power densities rise beyond 10 to 15 kW. Modern approaches include:
Direct-to-chip liquid cooling where cold plates are mounted directly on CPUs, GPUs, or ASICs, and water or engineered coolant is circulated about them to extract the heat.
Single-phase liquid loops where coolant circulates throughout the system and transfers heat via heat exchangers.
Two-phase liquid cooling where coolant boils at the chip, absorbing large amounts of latent heat before condensing elsewhere in the loop.
Full immersion cooling, in which entire servers are submerged in circulating dielectric fluid, allowing heat to be transferred directly from components to liquid.
At the facility level, several heat rejection strategies are used:
Evaporative cooling towers which are energy-efficient but water-intensive. These systems offer low operating costs in water-rich regions but face growing regulatory scrutiny and siting challenges in arid areas.
Dry air-cooled systems which eliminate most water use but require larger heat exchangers and consume more electrical power, increasing capital costs and slightly reducing overall efficiency.
Seawater or river-based heat exchangers which can provide excellent thermal performance at scale but impose strict geographic constraints and environmental permitting requirements.
Closed-loop cooling systems use sealed liquid loops to remove heat from the equipment and then reject that heat to the atmosphere using air-cooled radiators, minimizing water use at the expense of higher capital cost. Hybrid systems supplement this with limited evaporative cooling to improve performance during peak heat loads.
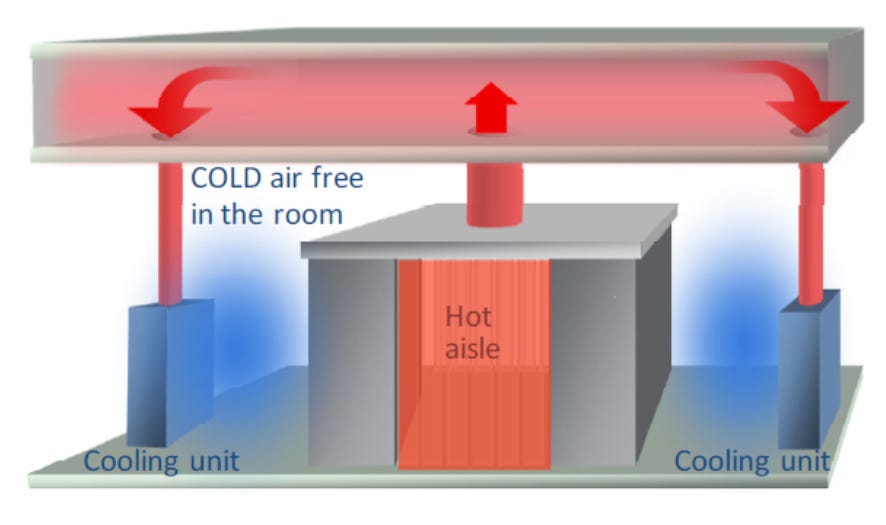
These thermodynamic constraints explain why terrestrial data centers increasingly resemble industrial cooling plants. In space-based systems, heat cannot be rejected to air or water and must instead be radiated directly to space, making radiator area and operating temperature the dominant thermal constraints.
EARTH-BASED SOLUTIONS
All existing data centers are currently on Earth, numbering over 12,000 globally. Current infrastructure leverages access to electrical power (modern hyperscale data centers require tens to hundreds of megawatts), a mature internet infrastructure with low-latency connectivity to end-users, and existing means and processes for constructing industrial centers (construction, maintenance, workforce, regulatory).
Earth is particularly well suited to training-heavy workloads, which concentrate enormous compute and power into centralized clusters. Training is insensitive to end-user latency, favors dense networking, and rewards economies of scale in power delivery and cooling. These characteristics naturally align with large terrestrial facilities optimized around firm power sources and advanced thermal management.
Earth currently excels where compute must be centralized, power-dense, and continuously expandable. The question is how far terrestrial architectures can be pushed before constraints become limiting.

Power on Earth: Moving from Grid Dependence to Behind-the-Meter Generation
Historically, data centers were designed as large but conventional grid-connected loads. Power was treated as a commodity input, priced by the market, and scaled incrementally as facilities expanded. That model is no longer sustainable in the setting of rapidly growing, AI-driven demand.
Modern hyperscale data centers require tens to hundreds of megawatts of continuous, reliable power. This load profile resembles heavy industry more than commercial real estate. In major U.S. markets, the ability to secure a utility power connection can take several years. Grid connection has emerged as a major bottleneck to data center expansion. In some cases, completed data center facilities have reportedly sat idle while awaiting power delivery.
These delays occur alongside growing public and regulatory scrutiny. In multiple regions, large data centers have drawn backlash over perceived impacts on electricity prices, grid reliability, and local infrastructure, further complicating permitting and expansion.4

These challenges are compounded by the characteristics of AI workloads themselves. Training clusters operate at high utilization for extended periods. While wind and solar can contribute meaningfully to overall energy supply, they do not by themselves provide the continuous reliable power required to support dense compute without extensive overbuild and backup storage.
In response, data center operators are shifting from grid dependence toward behind-the-meter and dedicated generation models. These approaches include long-term power purchase agreements tied to specific assets, co-locating data centers near generation sources, and developing on-site or adjacent power infrastructure. The objective is not only improved reliability, but greater control over availability, long-term cost structure, and development timelines.
Several on-Site and adjacent power options are now being evaluated or deployed to support large data center loads:
Natural gas including combined-cycle plants and aeroderivative or industrial gas turbines, offer relatively fast deployment timelines, but introduce fuel price volatility.
Small modular nuclear reactors and co-located nuclear facilities provide reliable continuous high-capacity power aligning well with data center load profiles but requiring longer planning and regulatory lead times.
Renewables paired with large-scale battery storage can reduce grid draw but become capital-intensive at the scale and duration required to support continuous AI workloads.
Temporary or bridging solutions, such as mobile gas turbines or jet-engine-based generators, are sometimes used to accelerate commissioning but are generally unsuitable as long-term anchors due to cost and emissions.
Among these options, nuclear power stands out as uniquely well matched to the scale, reliability, and operating profile of AI-driven data centers.
Nuclear-Powered Data Centers
Nuclear power can provide the continuous, reliable, and high-capacity electricity that modern data centers require, particularly those supporting training workloads. Unlike many industrial loads, data centers do not cycle on and off, and unlike residential or commercial demand, they do not follow diurnal or seasonal patterns. Nuclear reactors are designed for precisely this regime: high uptime, stable output, and decades-long operating lifetimes.
Nuclear energy offers three attributes that are difficult to find in other powers sources:
Constant baseload power capable of operating at capacity factors above 90 percent.
Low marginal operating cost, once capital is deployed, providing long-term price stability for energy-intensive compute.
Zero operational carbon emissions, addressing regulatory and investor pressure around sustainability without relying on offsets or overbuild.
These characteristics make nuclear particularly attractive for training-centric, centralized data centers, where power availability and reliability dominate all other constraints.
Co-location and Dedicated Nuclear Supply Solutions
Interest in nuclear-backed data centers has taken two primary forms. The first is co-location, where new data centers are sited near existing nuclear plants to leverage surplus capacity, minimize transmission losses, and reduce interconnection timelines. In these configurations, nuclear plants effectively function as anchor generation assets for digital infrastructure, converting electrical output directly into compute.
A prominent example is Talen Energy’s sale of a 960-MW nuclear-powered data center campus at the Susquehanna Nuclear Plant in Pennsylvania to Amazon Web Services (AWS) for $650 million. This transaction is widely cited as one of the first large-scale demonstrations of nuclear energy directly underpinning hyperscale cloud infrastructure.
Another model uses long-term nuclear power purchase agreements to anchor data center expansion. Constellation Energy’s 20-year agreement with Microsoft, which supports the planned restart of Three Mile Island Unit 1 in Pennsylvania, is intended to provide carbon-free electricity to Microsoft’s growing data center footprint while preserving firm electricity generation on the regional grid.
The second approach involves dedicated nuclear generation with advanced and small modular reactors (SMRs), developed explicitly to serve large data center loads. These projects offer the possibility of tighter integration between power generation, cooling systems, and compute infrastructure.
Several advanced nuclear developers, including Aalo Atomics and Valar Atomics, are explicitly positioning their first deployments around data-center-adjacent use cases. In August 2025, Aalo Atomics broke ground on their first advanced 10 MW nuclear power plant by Idaho National Laboratory (INL). This plant will power a co-located data center to be built in parallel. Valar Atomics broke ground in September 2025 at the Utah San Rafael Energy Lab (USREL) for its Ward 250 test reactor. Both projects are part of the U.S. Department of Energy (DOE) Reactor Pilot Program.

Nuclear and Thermal Integration
Nuclear-backed data centers also enable better thermal integration. Nuclear reactors produce large quantities of low-grade waste heat after electricity generation, which ordinarily must be rejected to the environment. In integrated configurations, a portion of this waste heat can instead be diverted to power absorption chillers or other thermally driven cooling equipment, reducing the amount of electrical power required for data center cooling. This integration does not eliminate the need to reject heat from the facility, but it can improve overall site efficiency by shifting part of the cooling load from electricity to thermal energy that would otherwise be wasted. This approach is most practical in large, continuously operated facilities where steady heat output and steady cooling demand coincide.

ORBIT-BASED SOLUTIONS
Given energy and cooling constraints on Earth, the idea of building AI infrastructure in orbit is coming to fruition. Instead of grid interconnection and water availability, space-based systems are governed by launch mass, radiation hardening, solar power generation area, and radiative heat rejection. Continuous or near-continuous access to solar energy in certain orbits enables power generation without fuel, transmission infrastructure, or grid congestion. In vacuum, heat can be rejected directly to space via radiation, eliminating dependence on air or water as heat sinks.

Power in Orbit: Solar as the Primary Energy Source
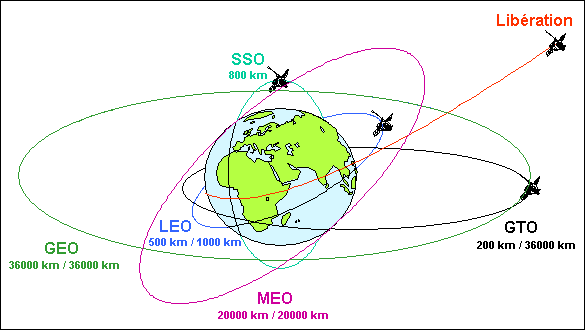
Orbital systems generate power locally with photovoltaic solar arrays. Outside of Earth’s atmosphere, solar panels have higher capacity factors due to the absence of cloud cover and reduced atmospheric attenuation. In sun-synchronous orbit (SSO) exposure to sunlight is predictable and in geostationary orbits (GEO) solar availability can approach continuous for most of the year. Solar power scales with surface area, and therefore mass.
At 1 Astronomical Unit (AU), the Sun delivers about 1.36 kW per square meter. On-orbit system efficiency is about 20% to 25% (and likely to improve). So, for example, 100 MW of power generation would require a 330,000 square meter solar array or 0.33 square kilometers (km), and the accompanying mass and support structures. Solar cell efficiency can improve this, but the overall relation between area and power delivered remains. A distributed constellation like Starlink addresses this at the unit level.
LEO is 300 to 1,200 km above the Earth’s surface and where most satellites reside. The orbital period is about 90 minutes, of which roughly 60 minutes are exposed to sunlight and 30 minutes are in eclipse. Onboard batteries are charged while in sunlight to power the satellite during the eclipse periods. Because it is closest to Earth, there is low latency and it is most accessible by launch.
Sun-Synchronous Orbit (SSO) is a specific type of LEO at near-polar latitudes. The satellite crosses the equator at the same local solar time daily, ensuring consistent lighting for Earth observation. SSO satellites still pass behind Earth every period and therefore need battery backup just like other LEO satellites, however they do have predictable and high average solar exposure.
GEO is much higher above the Earth’s surface at 35,786 km. GEO satellites are fixed above one longitude and therefore have a period of 24 hours. They are exposed to sunlight about 95% of the time. Because of their distance above Earth, latency is might higher, servicing is harder, launch is less accessible, and the radiation environment is different and more challenging.
Cooling in Orbit: Radiative Heat Rejection
In space, convection and evaporation are unavailable. On Earth, data centers reject heat by moving it into air or water and then to a final sink like the atmosphere, rivers, lakes, or the ocean. In the vacuum of orbit, this convection is not an option. Without a fluid to carry heat away, the only option is thermal radiation. Radiator size scales with heat load and operating temperature. Because nearly all electrical power consumed by compute ultimately becomes waste heat, scaling orbital compute power directly drives radiator area and mass.
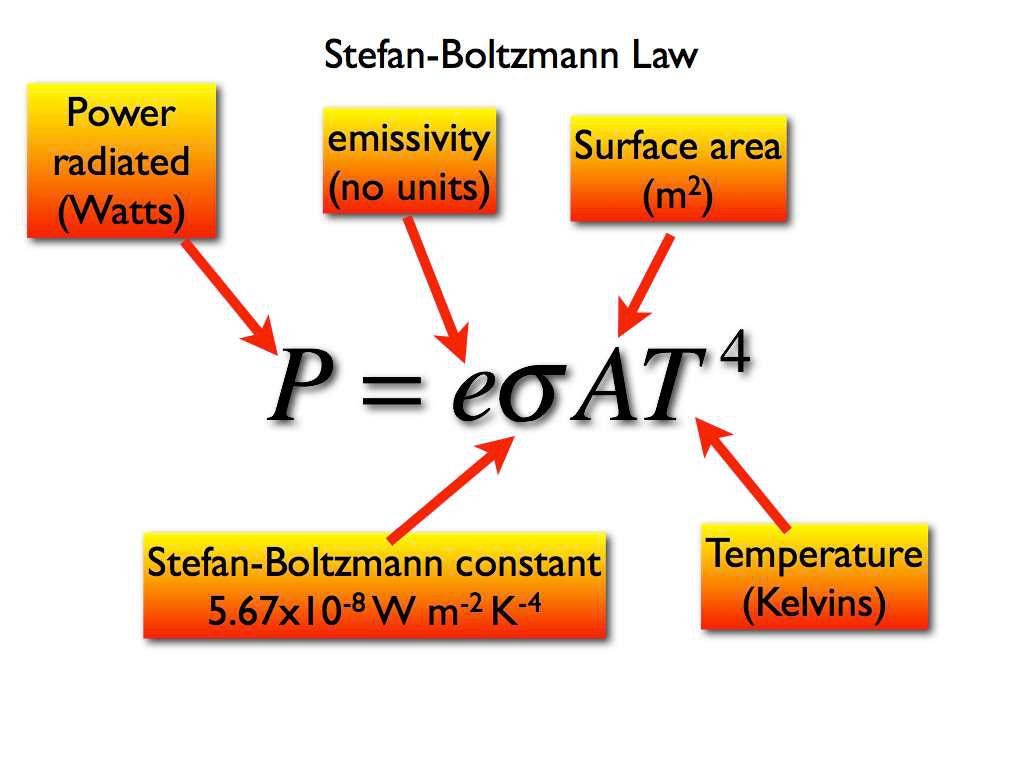
The fundamental constraint is set by the Stefan–Boltzmann law, which shows that the rate of heat rejection is proportional to radiator surface area and to the fourth power of operating temperature. As a result, systems that can tolerate higher operating temperatures can reject the same amount of heat with dramatically smaller radiators, while conservative temperature limits require very large radiator structures.
The thermal pathway for cooling in space is typically:
CHIP → COLD PLATE → FLUID LOOP → RADIATOR PANELS → DEEP SPACE
This is standard spacecraft thermal architecture: conduct heat away from components, transport it with heat pipes or pumped loops, and then reject it using radiators.
The fundamentals of radiative heat rejection in space set up two different strategies for accomplishing compute in orbit:
Large orbital data centers single center of compute powered by a large solar array all of which concentrates waste heat which will require large radiative cooling capacity. The Starcloud orbital data center plan is an example of this approach.
Distributed edge compute spreads compute across many satellites. Each satellite only needs radiators sized for kilowatt-class heat loads. The SpaceX Starlink V3 data center plan is an example of this approach.
CASE STUDY: Starcloud Orbital Data Centers

Starcloud represents the centralized approach to space-based data centers. Starcloud is designing large, power-dense orbital platforms that more closely resemble terrestrial hyperscale data centers. The core thesis is that energy and permitting constraints on Earth, rather than compute technology itself, are the bottlenecks to AI infrastructure growth.
Starcloud’s systems integrate solar power generation, liquid-cooled GPU compute, high-bandwidth optical networking, and large deployable radiators into a single orbital platform. Heat is removed via direct-to-chip liquid cooling and transported to radiator panels, which reject waste heat to space
Starcloud is initially deploying small satellites for demonstration and early revenue-generation. Starcloud’s first spacecraft Starcloud-1, launched in November 2025, flies an NVIDIA H100 GPU, which is about 100X more compute than has previously operated in orbit. Starcloud-2, scheduled for October 2026 will increase this compute by an order of magnitude and introduce AWS Outposts hardware to provide edge services to defense and commercial satellite customers

The long-term scaling target is 40 MW modules packaged within Starship payload volumes, with plans to deploy multiple units in proximity to form gigawatt-scale orbital clusters. Because these platforms are unconstrained by land, water, grid or interconnection, capacity can be expanded, presumably more quickly, on orbital timelines bounded by launch schedules rather than terrestrial permitting timelines.
Starcloud’s economic argument is based on the comparison between lifetime terrestrial electricity costs and launch plus solar deployment costs. For a 40 MW data center operating over a typical five-year GPU lifecycle, electricity expenses alone would be about $175 million on Earth at current power prices. By contrast, Starcloud estimates that launch and solar infrastructure for an equivalent orbital system could be on the order of tens of millions of dollars, with no ongoing fuel or grid costs. This model will be increasingly compelling as launch costs continue to decrease.
Starcloud has addressed technical constraints by operating hardware at higher allowable temperatures and by investing heavily in large, low-mass deployable radiator systems, which the company views as a core piece of intellectual property with applications beyond data centers, including space nuclear power systems and space manufacturing. Radiation exposure is managed through a combination of orbital selection, shielding, component testing, and software mitigation. Larger satellites benefit from favorable scaling laws: shielding mass scales with surface area, while compute scales with volume, making higher-power platforms proportionally easier to protect than smaller ones.

CASE STUDY: SpaceX Distributed Orbital Edge Compute
 – Royalty-Free Vector | VectorStock")
SpaceX is advancing a distributed approach to orbital compute by integrating it into the Starlink constellation, spreading processing capability across thousands of satellites rather than concentrating it in a large platform. Instead of scaling power generation, compute, and thermal rejection within a single structure, SpaceX scales by replication, adding incremental compute capacity with each new satellite launch. This strategy builds directly on the existing, operational Starlink constellation and planned next-generation v3 satellites.
This approach mirrors how SpaceX scaled global connectivity with Starlink by treating satellites as repeatable, mass-produced units and scaling capability through constellation size. The Starlink constellation now numbers on the order of 9,000 satellites, with reported production capacity in the thousands per year. All Starlink satellites operate in LEO.
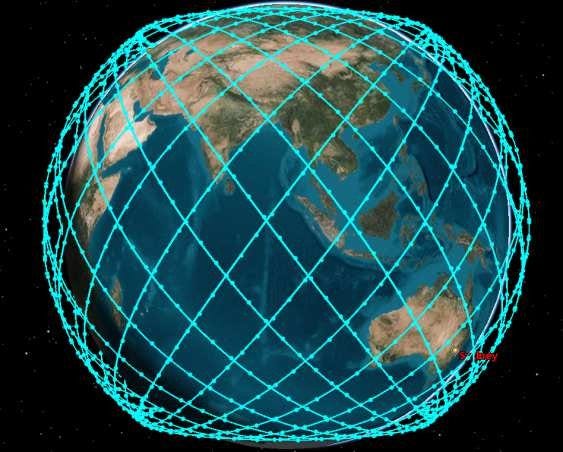
Each satellite generates power using photovoltaic arrays, stores energy in onboard batteries to bridge eclipse periods, and rejects waste heat using compact radiator surfaces sized for kilowatt-class power levels. By distributing compute across the constellation, each satellite remains within well-understood and flight-proven power and thermal regimes. Inter-satellite laser links provide high-bandwidth, low-latency communication between nodes, enabling distributed processing and coordination across orbital clusters.
In this model, thermal management is effectively solved once per satellite design and then replicated at scale through mass manufacturing. Power generation and cooling are tightly coupled to the satellite bus and scale naturally with constellation growth.
SpaceX has positioned Starlink as a global edge-compute layer, not as a replacement for terrestrial hyperscale data centers. Next-generation satellites are expected to incorporate more advanced onboard processing, enabling low-latency inference, and signal processing close to end users and space-based sensors. This architecture aligns well with inference-heavy workloads, which are latency-sensitive but far less power-intensive than centralized training.
SpaceX’s economic advantage derives from vertical integration, high-rate manufacturing, and ownership of launch capability. Reusable launch vehicles, most notably the anticipated Starship, are intended to drive launch costs down substantially over time, improving the economics of deploying and refreshing orbital compute capacity. By producing satellites in high volume and launching them on reusable rockets, SpaceX reduces the marginal cost of adding additional compute nodes and allows capacity to be expanded incrementally and continuously, rather than in large capital steps. The reported upcoming SpaceX IPO will help fund and accelerate this expansion.

INVESTMENT IMPLICATIONS
AI-driven data centers are emerging as one of the largest new industrial asset classes. They are not constrained by compute technology as much as by access to power, cooling, land, and time.
Data Centers are Industrial Assets
Research from Goldman Sachs and McKinsey frames data centers as a structurally new category. For investors, data center value is not only based on compute performance, but also on:
Secured access to long-duration, firm power
Ability to scale capacity on predictable timelines
Lifetime energy and cooling costs rather than marginal electricity prices
Power Is the Primary Economic Moat
For modern AI data centers, electricity cost can rival or exceed the cost of the hardware itself. As a result, hyperscale operators are transitioning from passive grid customers to active participants in power generation and infrastructure development.
Key investment consequences include:
Firm power premiums: AI training workloads operate at sustained high utilization and are poorly matched to intermittent generation alone. Assets that deliver 24/7 low-marginal-cost power, especially co-located nuclear and space-based solar are critical.
Behind-the-meter generation: Co-located or dedicated generation reduces exposure to multi-year grid interconnection delays and regulatory risk.
Vertical integration incentives: Hyperscalers increasingly underwrite power projects directly, compressing timelines even at higher upfront cost.
Nuclear and space-based solar technology are critical investment areas underpinning data centers on Earth and in space.
Thermal Management is a Second Moat
On Earth, rising rack densities push data centers away from air cooling and toward liquid and immersion systems, increasing capital intensity while tightening water and permitting constraints. In orbit, heat must be rejected via radiation, making radiator mass and operating temperature dominant cost drivers.
Earth and Orbit Are Complementary Not Competing Solutions
The emerging picture is not a zero-sum competition between Earth-based and space-based data centers. What is emerging is a layered compute stack:
Terrestrial hyperscale facilities dominate training and bulk inference, where dense networking, massive power, and economies of scale are decisive.
Orbital platforms support specialized workloads where terrestrial constraints dominate, such as sovereign compute, space-based sensing, or capacity unconstrained by land and permitting.
Distributed orbital constellations enable low-latency inference and edge compute, analogous to content delivery networks in terrestrial cloud architecture.
This mirrors the historical evolution of cloud and edge computing and suggests multiple winners across architectures.
Time-to-Scale is a Differentiator
A critical investor insight is that time is now as valuable as cost. AI model development cycles move faster than power permitting, grid upgrades, and land-use approvals. Capital favors platforms that compress development timelines, even if costs are higher:
Terrestrial data centers face multi-year delays tied to interconnection and permitting.
Orbital systems trade launch and mass constraints for speed, modularity, and incremental expansion.
Distributed constellations enable continuous capacity addition rather than capital intense step expansions.
Strategic Optionality and Second-Order Upside
Both nuclear-backed terrestrial data centers and orbital platforms embed strategic optionality beyond compute alone. Power assets can outlive hardware cycles, thermal systems have cross-sector applicability, and orbital infrastructure opens non-terrestrial markets spanning defense, communications, and space manufacturing.
DATA CENTER INFRASTRUCTURE LANDSCAPE
Modern data centers on Earth and in space rely on a layered infrastructure stack. As compute density rises, value increasingly comes from control of power, cooling, deployment speed, and physical constraints. Companies can be divided into:
Hyperscale and AI compute operators
Data center platforms
Compute hardware
Thermal management
Power generation
Transport and deployment infrastructure
Hyperscale and AI Compute Operators
These firms anchor global compute demand and increasingly act as infrastructure architects.
Amazon Web Services (AWS)
Microsoft Azure
Google Cloud Platform
Meta Platforms
Apple
Oracle
Starcloud
SpaceX
Voltage Park
Crusoe
Hyperscalers are underwriting power generation, reshaping cooling architectures, and compressing deployment timelines.
Data Center Platforms
Land, power access, and cooling at hyperscale
These firms provide physical infrastructure like land, power access, and cooling.
Equinix
Digital Realty
CyrusOne
NTT Global Data Centers
Vantage Data Centers
STACK Infrastructure
EdgeConneX
Power connection timelines increasingly dominate site selection and project viability.
Compute Hardware
NVIDIA
Advanced Micro Devices (AMD)
Intel
Broadcom
Hewlett Packard Enterprise
Dell Technologies
Lonestar Data Holdings
Thermal Management
Cooling now drives capital cost, siting risk, and permitting outcomes.
Vertiv
Schneider Electric
Johnson Controls
LiquidStack
Submer
Ramon.Space
Aerospace thermal suppliers
Power Generation
Access to firm power increasingly defines data center feasibility.
Kairos Power
TerraPower
Aalo Atomics
Valar Atomics
Constellation Energy
Energy Northwest
Aetherflux
EMF Space
Transport and Deployment Infrastructure
This layer governs how fast capacity can be added.
EPC firms, substations, transmission developers
SpaceX
Blue Origin
Phantom Space
Deployment velocity is becoming as important as unit economics.
LOOK TO THE FUTURE
The rise of data centers represents a reindustrialization movement that sits at the intersection of electricity generation, thermodynamics, manufacturing scale, and the new space economy. As compute continues to scale, the limiting factors are not related to the computing hardware. The limiting factors are the physical systems that make computation possible at industrial scale.
The decisive advantages will accrue not to those who master:
Firm, scalable power capable of sustaining continuous, high-density compute
Thermal pathways that can reject heat as efficiently as it is generated
Deployment timelines that align with the pace of model development rather than the pace of permitting and grid expansion
Earth and orbit will not compete. Compute infrastructure will evolve by leveraging the unique benefits of Earth-based data centers, Space-based data centers, and Space-based distributed compute. Terrestrial hyperscale infrastructure, increasingly anchored by nuclear power and advanced cooling, will remain the backbone of global training and bulk inference. Centralized and distributed orbital platforms will extend compute beyond terrestrial constraints.
 | A guest post by
|